
Every day, a vast quantity of textual information is written or printed on tangible paper, such as study-related messages, invoices, periodicals, books, ads, and so on. Paper contamination is a major issue in the corporate world and has obvious environmental consequences. Aside from that, it will be difficult to keep a large quantity of information or conduct a quick look for information if we use physical paper in business. Both STS Software and the clients are affected by these issues.

Introduction

Recent advances in science and technology, particularly in the field of artificial intelligence, have given us the inspiration to create innovative ways to address the issue of paper pollution, such as an automated system to transfer all textual information currently stored on paper to a digital format.

Recent advances in science and technology, particularly in the field of artificial intelligence, have given us the inspiration to create innovative ways to address the issue of paper pollution, such as an automated system to transfer all textual information currently stored on paper to a digital format.
Our Approaches
Our purpose is to convert text image data to text and then process the output text to extract some important information. To do that, we have applied some Deep Learning models in Computer Vision to detect the text location on the natural image and then recognize some specific words. We separate our system into multi parts from pre-processing input images to get the final meaning of the text.
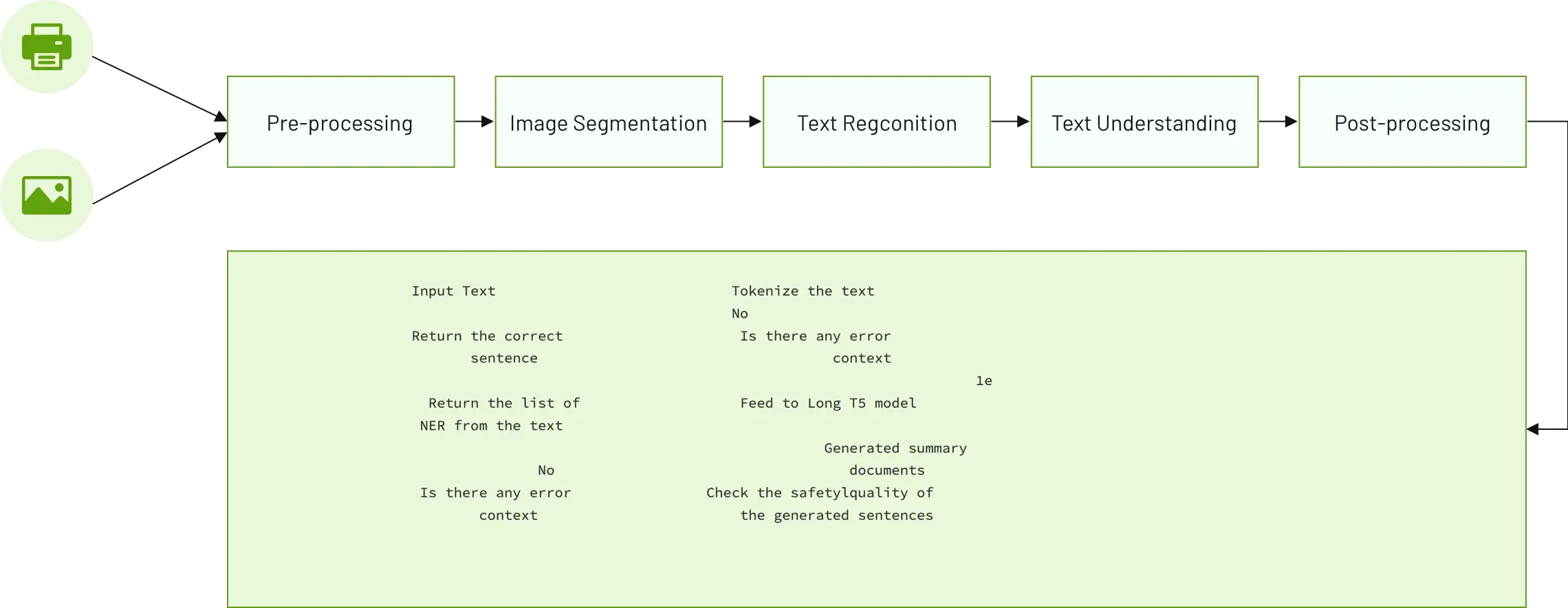
As you can see, firstly our system will receive data from the input text image or printed image... This input data will be cleaned or pre-processed by some methods like enhancing the image quality, removing blur, noise, and normalization. Then, the system will run some Deep Learning models to detect the text region on the cleaned input image and recognize, classify each text to some specific word, and at this step, we will have the output text data. Finally, there is an NLP model to clean again this text data to make these text data meaningful and extract the necessary information from them.
Related Projects
AI and ML

Analyze The Object On Image Using Computer Vision Technologies
With the help of Computer Vision techniques, this effort seeks to create a system that can evaluate the Object on Image.
Detail
AI and ML

CVParser Documents
This project aims at developing an end-to-end system, CV Parser System, to extract important information from a .pdf CV file automatically. As Artificial Intelligence has gained a reputation recently, applying the Computer Vision or Natural Language Processing technologies.
Detail
AI and ML

Natural Language Processing Toolkit
The Natural Language Processing Toolkit (NLTK) is a Python-based software application that offers a suite of tools for the purpose of processing natural language data.
Detail
AI and ML

Music Recommendation System
Music Recommendation Systems have become immensely popular, enabling users to explore new songs and artists based on their listening habits and preferences.
Detail
AI and ML

Product Recognition
Utilizing AI-based Computer Vision techniques, the Product Recognition system autonomously detects and categorizes products present within images or videos. Through a comprehensive analysis of the visual attributes of products, including their shapes, colors, and textures
Detail
AI and ML

Skin Analyzing System
A skin analysis system evaluates skin health and appearance using imaging, machine learning, and data analysis to assess conditions like acne, wrinkles, and sun damage.
Detail
AI and ML

Semantic Search For Travel Place Document
This project aims at developing a Semantic Searching Engine that could search with meaning not only to find keywords but to determine the intent and contextual meaning of the input sentence.
Detail
Choose STS Software for Your Next AI Development Project
Ready to take your project to the next level? Reach out to us now, and let's explore the best solution for your needs!