
This project aims at developing an end-to-end system, CV Parser System, to extract important information from a .pdf CV file automatically. As Artificial Intelligence has gained a reputation recently, applying the Computer Vision or Natural Language Processing technologies.

INTRODUCTION

STS Software is the leading software outsourcing company in US, established in 2012 with the power of more than 350 top-tier software engineers and a mature process. Each month, we receive a large number of resumes from potential employees. Meaning we have to sort through a mountain of CVs.

In addition, when looking for a good applicant, we consult some online tools or other sources such as LinkedIn... The standard procedure involves our Talent Acquisition (TA) team manually checking each CV file to get the information, then passing it along to the Tech Lead and Project Manager for review and interview. Finally, it is passed along to the Human Resources (HR) team for processing, making the contract, updating the candidate's personal information to our system, etc.

STS Software also boasts a strong AI team with a lot of experience in developing the AI software solution, our AI team has joined many similar projects before that providing our customer some AI solutions to process the big dataset and create the very powerful system with high performance, so we have applied these technologies and create an end to end system to process automatically the CV data, the CV Parser system.
Our Approaches
There are many available tools or PDF reader modules, and libraries... to read the text layer from the .pdf file. But these outputs are only the text which is arranged line by line, the received information is messy and meaningless. For our issue, extracting the necessary information from a .pdf CV file, we will have to face up to some problems below:
The structure of CV files is so varied, and they are not in the same format.
It is difficult to cluster all related sections together.
It is hard for machines to know the meaning of each text data.
We will need a lot of rules to clean that text information,...
However, some state-of-the-art AI technologies could deal with the above issues, so we have built an end-to-end system, CV Parser, that could help us automatically parse all meaningful information from a .pdf file. Our system architecture was divided into 3 main parts:
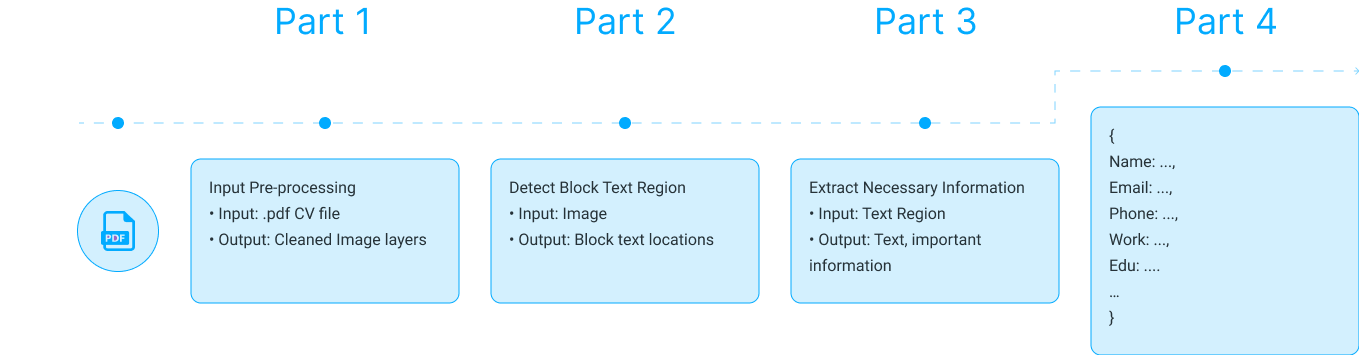
• In the first part, the system will receive the uploaded .pdf file from the client, clean this data, and convert this pdf data to image data.
• In the second part, by applying the Image Processing algorithms and Computer Vision models, the CV Parser system could analyze the structure of the CV and recognize the CV document layout.
• In the final part, each document location will be processed by the OCR, Natural Language Processing model to understand the meaning of text data.
Related Projects
AI and ML

Analyze The Object On Image Using Computer Vision Technologies
With the help of Computer Vision techniques, this effort seeks to create a system that can evaluate the Object on Image.
Detail
AI and ML

Natural Language Processing Toolkit
The Natural Language Processing Toolkit (NLTK) is a Python-based software application that offers a suite of tools for the purpose of processing natural language data.
Detail
AI and ML

Music Recommendation System
Music Recommendation Systems have become immensely popular, enabling users to explore new songs and artists based on their listening habits and preferences.
Detail
AI and ML

Product Recognition
Utilizing AI-based Computer Vision techniques, the Product Recognition system autonomously detects and categorizes products present within images or videos. Through a comprehensive analysis of the visual attributes of products, including their shapes, colors, and textures
Detail
AI and ML

Skin Analyzing System
A skin analysis system evaluates skin health and appearance using imaging, machine learning, and data analysis to assess conditions like acne, wrinkles, and sun damage.
Detail
AI and ML

Semantic Search For Travel Place Document
This project aims at developing a Semantic Searching Engine that could search with meaning not only to find keywords but to determine the intent and contextual meaning of the input sentence.
Detail
AI and ML

Optical Character Recognition Document
Every day, a vast quantity of textual information is written or printed on tangible paper, such as study-related messages, invoices, periodicals, books, ads, and so on. Paper contamination is a major issue in the corporate world and has obvious environmental consequences.
Detail
Choose STS Software for Your Next AI Development Project
Ready to take your project to the next level? Reach out to us now, and let's explore the best solution for your needs!